
La Continuité de Service Informatique : Assurer la Résilience des Systèmes
Définition
La continuité de service informatique regroupe l'ensemble des mesures et des pratiques mises en place pour garantir que les services informatiques restent disponibles et fonctionnels, même en cas d'incident ou de perturbation. L'objectif principal est de minimiser les interruptions de service et de permettre une reprise rapide et efficace des activités après un événement perturbateur.
Gestion des Incidents Informatique
Incident Mineur
Un incident informatique mineur est un événement ayant un impact limité sur les opérations de l'entreprise et pouvant être résolu rapidement avec peu ou pas de perturbations. Ces incidents sont souvent gérés par le support technique de manière routinière. La tolérance aux pannes et la haute disponibilité permettent d'assurer la continuité du service.
Tolérance aux Pannes
La tolérance aux pannes permet à un système de continuer à fonctionner en cas de défaillance d'un composant. Pour un serveur physique, cela peut inclure :
- Alimentation redondante
- Disques en RAID
- Clusters de serveurs
- Virtualisation avec basculement automatique
Haute Disponibilité
La haute disponibilité garantit un temps de fonctionnement maximal grâce à la redondance des infrastructures et à des stratégies de basculement rapide.
RAID : Protection des Données
Le RAID est une technologie permettant de répartir et de protéger les données sur plusieurs disques.
| Mode RAID | Nb Min. Disques | Capacité Totale | Impact d'une panne |
|---|---|---|---|
| RAID 0 | 2 | Somme des disques | Perte totale si un disque tombe |
| RAID 1 | 2 | Capacité d'un disque | Aucune perte si un seul disque tombe |
| RAID 5 | 3 | (N-1) * Taille disque | Perte tolérée d'1 disque |
| RAID 6 | 4 | (N-2) * Taille disque | Perte tolérée de 2 disques |
| RAID 10 | 4 | (N/2) * Taille disque | Perte tolérée d'1 disque par paire |
Incident Informatique Majeur
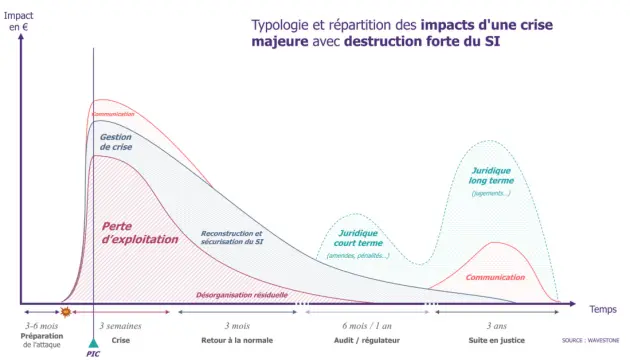
Un incident majeur est un événement urgent et à fort impact qui touche une partie importante de l'organisation, entraînant l'indisponibilité des services et impactant la situation financière.
Coût d'un Incident Majeur
Voici quelques exemples d'incidents ayant eu un impact financier significatif :
- Reckitt : 110 millions d'euros
- Saint-Gobain : 250 millions d'euros
- Maersk : 200-300 millions de dollars
Plan de Gestion de Crise (PGC)
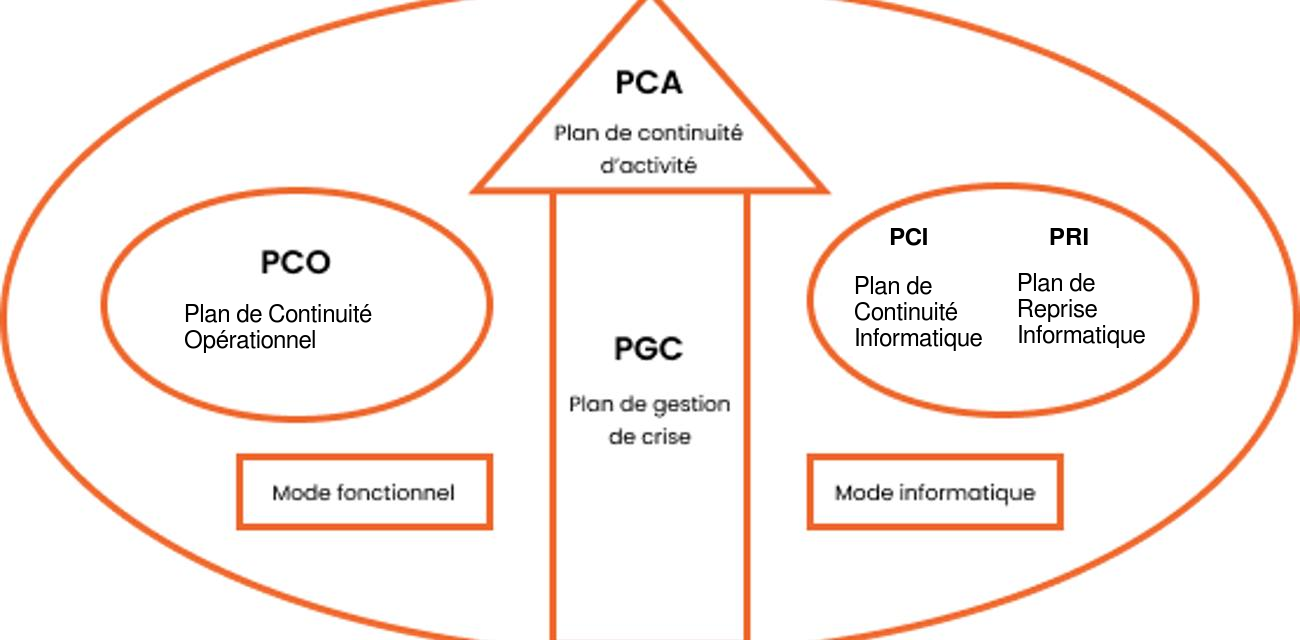
Le PGC regroupe les mesures prises avant, pendant et après une crise informatique. Ses composantes incluent :
- Plan de Continuité Informatique (PCI)
- Plan de Reprise Informatique (PRI)
PCI et PRI
- Plan de Continuité Informatique (PCI) : Assure la disponibilité continue des services informatiques.
- Plan de Reprise Informatique (PRI) : Concentre sur la restauration rapide des systèmes après une interruption majeure.
RPO et RTO
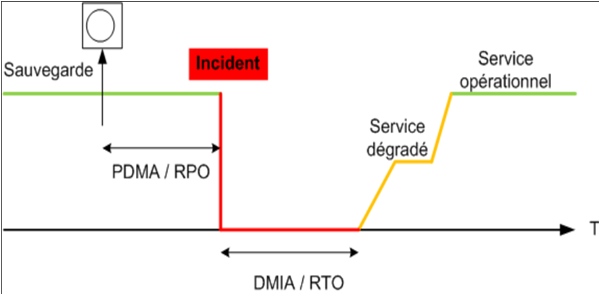
| Terme | Définition |
|---|---|
| RPO (Recovery Point Objective) | Durée maximale de perte de données admissible |
| RTO (Recovery Time Objective) | Délai maximal pour restaurer un système |
Stratégies de Continuité Informatique
Pour minimiser les interruptions, les entreprises mettent en place diverses solutions :
- Surveillance continue des systèmes
- Redondance des infrastructures
- Sauvegardes régulières et externalisées
- Sites de secours et virtualisation
Conclusion
Assurer la continuité d'un service informatique est essentiel pour maintenir la productivité et limiter les pertes financières. La mise en place de plans solides comme le PCI et le PRI, ainsi que l'utilisation de technologies telles que le RAID, les clusters et la virtualisation, permettent d'assurer la résilience des infrastructures informatiques.